Configuring a Neural Network Output Layer
Configuring a Neural Network Output Layer - Enthought, Inc.
If you have used TensorFlow before, you know how easy it is to create a simple neural network model using the Keras API.
Just create an instance of the Sequential model class, add the number of desired layers and accompanying layer nodes, define the activation functions to be used by each layer, and compile your model by providing an optimizer and loss function. Right?
While this process is simple enough to grasp conceptually, it can quickly become an ambiguous task for those just getting started in deep learning.
Why does the output layer take a different shape between a regression and classification problem?
Is there a reason why one online tutorial solved a binary classification problem using a network with only one node in the output layer, while another tutorial solved the same problem using two nodes?
And, what about the activation function on the final layer of a network when performing classification – why is there a softmax and sigmoid?
Do I really need to specify a different loss function for different types of classification problems?
When I first started my deep learning journey, I had the same kinds of questions, but did not find any answers readily available. Now, as an Instructor at Enthought, I’m helping scientists and engineers across multiple industries overcome this same type of hurdle. The result is this blog post—which is one of my favorite resources from the Enthought Training team.
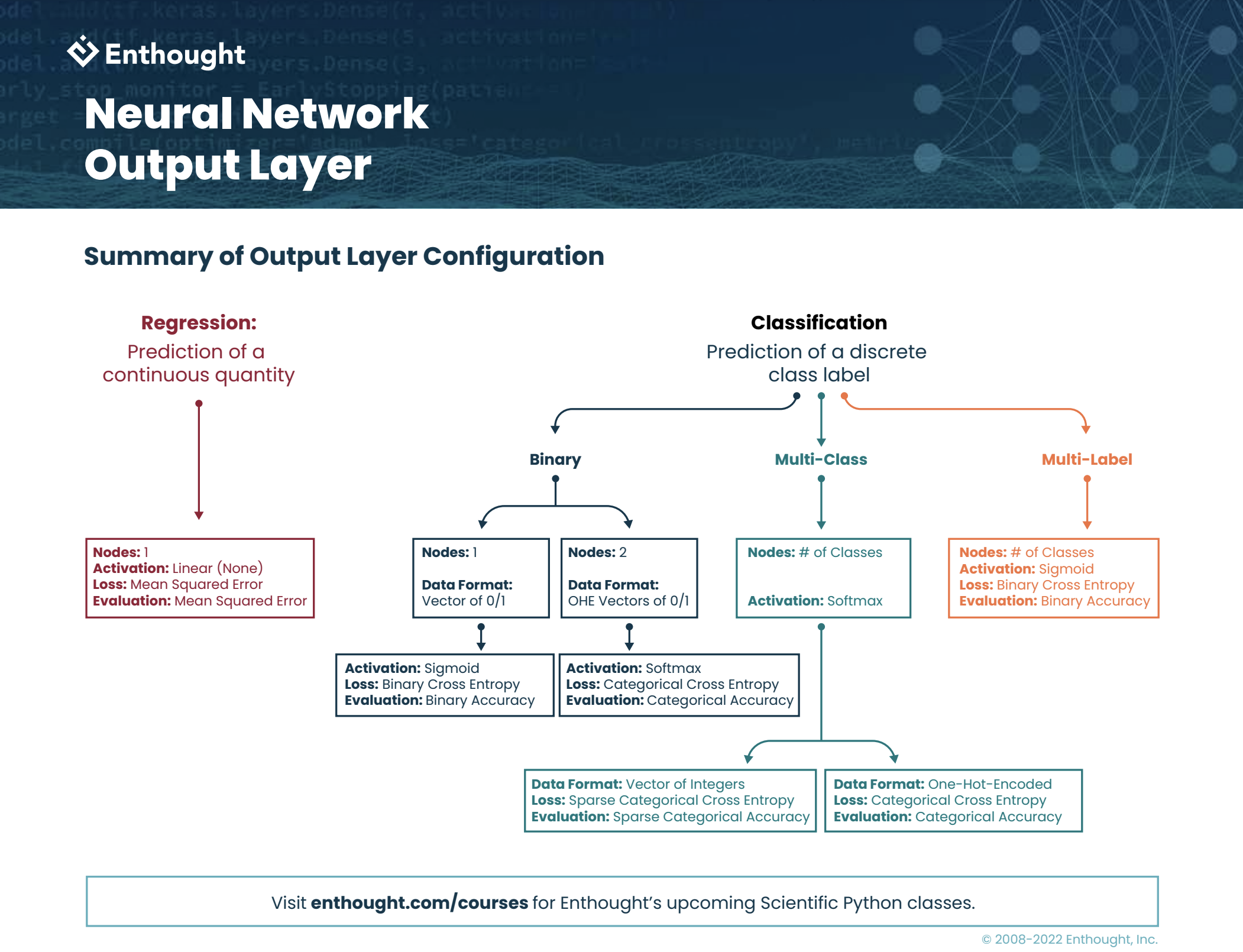
Image developed by Erick Michaud (@earache73)